MoonXi-net: A Deep Learning Training Framework Built with MoonBit

Original author: Li Kaiwei, Ph.D. in Computer Science and Technology, Tsinghua University.
Based on good system architecture design, MoonBit + domestic large language models + an open-source harness can implement a PyTorch-like deep learning training framework, with performance twice as fast as PyTorch. The development time was less than one month, and all of it was done in spare time.
Links
Origin
About a month ago, a colleague complained that writing Torch training code in Python was not type-safe for all kinds of things, and that code quality could not be guaranteed. As an old-school systems programmer who has worked on systems for many years, I keenly realized: is this not another good opportunity to reinvent the wheel? Seeing that the Rust wheel-reinventing project I had pushed hard for a year had already attracted a few colleagues to join, it was time to bring out MoonBit, which I had been thinking about for a long time. As expected, my colleagues were cautious and wanted to wait and see with the new language, so I took the opportunity to propose first putting something together at home in my spare time.
First Try
It is already 2026. Even if MoonBit has the fastest compilation speed in the universe and the fastest IDE navigation, one still cannot hand-write everything line by line in the old-fashioned way. Since this was an experiment anyway, I decided to use the leading domestic large model GLM-5.1 (DeepSeek V4 and Kimi K2.6 had not been released at the time), plus the blindly chosen oh-my-opencode, and got started directly.
Here I omit ten thousand words of complaints about wrestling with the CUDA environment in WSL.
With absolutely zero personal experience in PyTorch, the large model quickly put together the first version of MNIST, which made me very excited. So I told it to continue directly with CUDA. As expected, something unexpected happened: MoonBit did not support linking CUDA, or at least I did not figure it out. No big deal, I forked a version of the open-source moon toolchain, added my epic CMakeLists.txt experience, and got it done before long. After that it was mindless vibe coding. After waiting one night, the ResNet model actually ran, using the CIFAR-10 dataset. Do not ask why I chose that; it was only because I asked DeepSeek.
The turning point also came quickly. I asked it to put together PyTorch code for the same algorithm for comparison. Not only was it one hundred times slower, but the accuracy also did not match at all. Test accuracy was only 10%, no better than random guessing. Fine, I then realized I hadn’t included the evaluation harness. So I gave it another night to optimize efficiency and accuracy. The results were much better: it ended up only about 2× slower than native Python, with acceptable accuracy.
Iteration
Once the prototype ran, it was worth bragging about to colleagues. But no one could accept code that looked like noodles. So I had an in-depth architecture discussion with DeepSeek about whether a framework written in MoonBit should use a JAX style or a Torch style. After several rounds of dialogue, I, with zero PyTorch experience, gained quite a bit of understanding of basic concepts such as model, loss, grad, optimizer, and loader. Feeling pretty confident, I waved my hand and asked the AI to go ahead and build a JAX-style framework.
While writing MoonBit, AI produced many Rust syntax hallucinations. For example, for traits with generics, it tried to add them next to the name and near interface functions, all of which were mercilessly rejected by the compiler. It even tried to write a higher-kinded lambda function, and all attempts failed. After I do not know how many obstacles, the thing it finally wrote could run, but it was still far from my expectations.
If AI were a junior colleague I was mentoring, and after so much effort it still looked like this, would you blame it or start wondering whether your expectations were too high? Taking the attitude that whoever proposes an idea should take responsibility for it, I gave up all my illusions about AI and decided to go head-to-head with the compiler myself.
Plan
I organized my thoughts. First, it could not be written as purely dynamic types like PyTorch. Instead, CPU and GPU tensors needed to be defined as different types. At the same time, the model's forward function had to be written only once and be able to generalize. Also, computing backward gradients had to be done in one sentence, like PyTorch.
Tensor Trait
Define the Tensor trait, with various computational interfaces:
trait trait Tensor : Add + Sub + Mul {
fn dims(Self) -> FixedArray[Int]
fn zeros(dims : FixedArray[Int]) -> Self
fn scale(Self, Float) -> Self
fn square(Self) -> Self
fn mean(Self) -> Self
fn scalar(Float) -> Self
fn size(Self) -> Int
}
Tensor: trait Add {
fn add(Self, Self) -> Self
}
types implementing this trait can use the + operator
Add + trait Sub {
fn sub(Self, Self) -> Self
}
types implementing this trait can use the - operator
Sub + trait Mul {
fn mul(Self, Self) -> Self
}
types implementing this trait can use the * operator
Mul {
(Self) -> FixedArray[Int]
dims(type parameter Self
Self) -> type FixedArray[A]
FixedArray[Int
Int]
(FixedArray[Int]) -> Self
zeros(dims : type FixedArray[A]
FixedArray[Int
Int]) -> type parameter Self
Self
(Self, Float) -> Self
scale(type parameter Self
Self, Float
Float) -> type parameter Self
Self
(Self) -> Self
square(type parameter Self
Self) -> type parameter Self
Self
(Self) -> Self
mean(type parameter Self
Self) -> type parameter Self
Self
(Float) -> Self
scalar(Float
Float) -> type parameter Self
Self
(Self) -> Int
size(type parameter Self
Self) -> Int
Int
}
Define an implementation of Tensor, such as NpArray, and implement its computational functions. Dimension checks and other functions are omitted here.
struct NpArray {
FixedArray[Int]
dims : type FixedArray[A]
FixedArray[Int
Int]
FixedArray[Float]
data : type FixedArray[A]
FixedArray[Float
Float]
} derive(trait @debug.Debug {
fn to_repr(Self) -> @debug.Repr
}
Trait for types that can be converted to human-readable debugging info.
Debug)
impl trait Add {
fn add(Self, Self) -> Self
}
types implementing this trait can use the + operator
Add for struct NpArray {
dims: FixedArray[Int]
data: FixedArray[Float]
} derive(@debug.Debug)
NpArray with fn Add::add(x : NpArray, y : NpArray) -> NpArray
add(NpArray
x : struct NpArray {
dims: FixedArray[Int]
data: FixedArray[Float]
} derive(@debug.Debug)
NpArray, NpArray
y : struct NpArray {
dims: FixedArray[Int]
data: FixedArray[Float]
} derive(@debug.Debug)
NpArray) -> struct NpArray {
dims: FixedArray[Int]
data: FixedArray[Float]
} derive(@debug.Debug)
NpArray {
let Int
n = NpArray
x.FixedArray[Float]
data.fn[T] FixedArray::length(self : FixedArray[T]) -> Int
Returns the number of elements in a fixed-size array.
Parameters:
array : The fixed-size array whose length is to be determined.
Returns an integer representing the number of elements in the array.
Example:
test {
let arr = FixedArray::make(3, 42)
inspect(arr.length(), content="3")
}
length()
{ FixedArray[Int]
dims: NpArray
x.FixedArray[Int]
dims, FixedArray[Float]
data: type FixedArray[A]
FixedArray::fn[T] FixedArray::makei(length : Int, value : (Int) -> T raise?) -> FixedArray[T] raise?
Creates a new fixed-size array of the specified length, where each element is
initialized using a function that maps indices to values.
Parameters:
length : The length of the array to create. If length is less than or
equal to 0, returns an empty array.initializer : A function that takes an index (from 0 to length - 1) and
returns a value of type T for that position.
Returns a new fixed array containing the values produced by applying the
initializer function to each index.
Example:
test {
let arr = FixedArray::makei(3, i => i * 2)
debug_inspect(
arr,
content=(
#|<FixedArray: [0, 2, 4]>
),
)
}
makei(Int
n, fn(Int
i) { NpArray
x.FixedArray[Float]
datafn[T] FixedArray::op_get(self : FixedArray[T], idx : Int) -> T
Retrieves an element at the specified index from a fixed-size array. This
function implements the array indexing operator [].
Parameters:
array : The fixed-size array to access.index : The position in the array from which to retrieve the element.
Returns the element at the specified index.
Panics if the index is out of bounds.
Example:
test {
let arr = FixedArray::make(3, 42)
inspect(arr[1], content="42")
}
[i] fn Add::add(self : Float, other : Float) -> Float
Performs addition between two single-precision floating-point numbers.
Parameters:
self : The first floating-point operand.other : The second floating-point operand to be added to the first
operand.
Returns a single-precision floating-point number representing the sum of the
two operands.
Example:
test {
let a = Float::from_double(3.14)
let b = Float::from_double(2.86)
let sum = a + b
inspect(sum.to_double(), content="6")
}
+ NpArray
y.FixedArray[Float]
datafn[T] FixedArray::op_get(self : FixedArray[T], idx : Int) -> T
Retrieves an element at the specified index from a fixed-size array. This
function implements the array indexing operator [].
Parameters:
array : The fixed-size array to access.index : The position in the array from which to retrieve the element.
Returns the element at the specified index.
Panics if the index is out of bounds.
Example:
test {
let arr = FixedArray::make(3, 42)
inspect(arr[1], content="42")
}
[i] }) }
}
Note: broadcast computation for adding tensors of different dimensions is omitted here.
Model Forward
Define the model and implement its forward function:
struct Linear[T] {
T
w : type parameter T
T
T
b : type parameter T
T
}
fn[T : trait Tensor : Add + Sub + Mul {
fn dims(Self) -> FixedArray[Int]
fn zeros(dims : FixedArray[Int]) -> Self
fn scale(Self, Float) -> Self
fn square(Self) -> Self
fn mean(Self) -> Self
fn scalar(Float) -> Self
fn size(Self) -> Int
}
Tensor] struct Linear[T] {
w: T
b: T
}
Linear::fn[T : Tensor + Add + Sub + Mul] Linear::forward(self : Linear[T], x : T) -> T
forward(Linear[T]
self : struct Linear[T] {
w: T
b: T
}
Self[type parameter T
T], T
x : type parameter T
T) -> type parameter T
T {
T
x (_ : T, _ : T) -> T
* Linear[T]
self.T
w (_ : T, _ : T) -> T
+ Linear[T]
self.T
b
}
Functions such as loss are similar and are omitted here.
Grad
The main event is the automatic gradient Grad[T] (formally called Automatic Differentiation).
It is a generic wrapper. T can be NpArray, a future GPUTensor implementation, or even Grad itself if second-order gradients are required.
struct Grad[T] {
mut T
value : type parameter T
T
mut T
grad : type parameter T
T
}
It can also implement the Tensor trait. Note that backpropagation happens only during backward, so the operations need to be "recorded" first. This algorithm is called tape-based autograd.
Define a tape. It is an appendable array whose contents are closures of type () -> Unit, recording the backward gradient computations to be performed later:
let Array[() -> Unit]
tape : type Array[T]
An Array is a collection of values that supports random access and can
grow in size.
Array[() -> Unit
Unit] = type Array[T]
An Array is a collection of values that supports random access and can
grow in size.
Array::fn[T] Array::new(capacity? : Int) -> Array[T]
Creates a new empty array with an optional initial capacity.
Parameters:
capacity : The initial capacity of the array. If 0 (default), creates an
array with minimum capacity. Must be non-negative.
Returns a new empty array of type Array[T] with the specified initial
capacity.
Example:
test {
let arr : Array[Int] = Array::new(capacity=10)
inspect(arr.length(), content="0")
inspect(arr.capacity(), content="10")
let arr : Array[Int] = Array::new()
inspect(arr.length(), content="0")
}
new()
impl[T : trait Tensor : Add + Sub + Mul {
fn dims(Self) -> FixedArray[Int]
fn zeros(dims : FixedArray[Int]) -> Self
fn scale(Self, Float) -> Self
fn square(Self) -> Self
fn mean(Self) -> Self
fn scalar(Float) -> Self
fn size(Self) -> Int
}
Tensor] trait Add {
fn add(Self, Self) -> Self
}
types implementing this trait can use the + operator
Add for struct Grad[T] {
mut value: T
mut grad: T
}
Grad[type parameter T
T] with fn[T : Tensor + Add + Sub + Mul] Add::add(gx : Grad[T], gy : Grad[T]) -> Grad[T]
add(Grad[T]
gx : struct Grad[T] {
mut value: T
mut grad: T
}
Grad[type parameter T
T], Grad[T]
gy : struct Grad[T] {
mut value: T
mut grad: T
}
Grad[type parameter T
T]) -> struct Grad[T] {
mut value: T
mut grad: T
}
Grad[type parameter T
T] {
let T
value = Grad[T]
gx.T
value (_ : T, _ : T) -> T
+ Grad[T]
gy.T
value
let Grad[T]
out = { T
value, T
grad: T
value.() -> T
zeros_like() }
let tape : Array[() -> Unit]
tape.fn[T] Array::push(self : Array[T], value : T) -> Unit
Adds an element to the end of the array.
If the array is at capacity, it will be reallocated.
Example
test {
let v = []
v.push(3)
}
push( () => Grad[T]
gx.T
grad = Grad[T]
gx.T
grad (_ : T, _ : T) -> T
+ Grad[T]
out.T
grad) )
let tape : Array[() -> Unit]
tape.fn[T] Array::push(self : Array[T], value : T) -> Unit
Adds an element to the end of the array.
If the array is at capacity, it will be reallocated.
Example
test {
let v = []
v.push(3)
}
push( () => Grad[T]
gy.T
grad = Grad[T]
gy.T
grad (_ : T, _ : T) -> T
+ Grad[T]
out.T
grad) )
Grad[T]
out
}
The core is this closure: () => gx.grad = gx.grad + out.grad. The key point is that the closure captures both gx and out, so gx.grad can be assigned and updated, and the value of out.grad is accessed only when the closure is called, not when it is zero.
Then implement the backward function: set the loss gradient to 1 and play the tape backward:
fn[T : trait Tensor : Add + Sub + Mul {
fn dims(Self) -> FixedArray[Int]
fn zeros(dims : FixedArray[Int]) -> Self
fn scale(Self, Float) -> Self
fn square(Self) -> Self
fn mean(Self) -> Self
fn scalar(Float) -> Self
fn size(Self) -> Int
}
Tensor] struct Grad[T] {
mut value: T
mut grad: T
}
Grad::fn[T : Tensor + Add + Sub + Mul] Grad::backward(self : Grad[T]) -> Unit
backward(Grad[T]
self : struct Grad[T] {
mut value: T
mut grad: T
}
Grad[type parameter T
T]) -> Unit
Unit {
Grad[T]
self.T
grad = type parameter
T::(Float) -> T
scalar((1.0 : Float
Float))
for Int
i in let tape : Array[() -> Unit]
tapeInt
.fn[T] Array::length(self : Array[T]) -> Int
Returns the number of elements in the array.
Parameters:
array : The array whose length is to be determined.
Returns the number of elements in the array as an integer.
Example:
test {
let arr : ReadOnlyArray[Int] = [1, 2, 3]
inspect(arr.length(), content="3")
let empty : ReadOnlyArray[Int] = []
inspect(empty.length(), content="0")
}
lengthInt
()>..0 {
let tape : Array[() -> Unit]
tapefn[T] Array::op_get(self : Array[T], index : Int) -> T
Retrieves an element from the array at the specified index.
Parameters:
array : The array to get the element from.index : The position in the array from which to retrieve the element.
Returns the element at the specified index.
Throws a panic if the index is negative or greater than or equal to the
length of the array.
Example:
test {
let arr : ReadOnlyArray[Int] = [1, 2, 3]
inspect(arr[1], content="2")
}
[i]()
}
}
Main
Finally, implement gradient descent for the complete linear model:
fn main {
let Array[Float]
xs : type Array[T]
An Array is a collection of values that supports random access and can
grow in size.
Array[Float
Float] = [1.0, 2.0, 3.0, 4.0, 5.0]
let Array[Float]
ys : type Array[T]
An Array is a collection of values that supports random access and can
grow in size.
Array[Float
Float] = [4.0, 7.0, 10.0, 13.0, 16.0]
let Grad[NpArray]
w : struct Grad[T] {
mut value: T
mut grad: T
}
Grad[struct NpArray {
dims: FixedArray[Int]
data: FixedArray[Float]
} derive(@debug.Debug)
NpArray] = (Unit) -> Grad[NpArray]
no_grad(struct NpArray {
dims: FixedArray[Int]
data: FixedArray[Float]
} derive(@debug.Debug)
NpArray::(Float) -> Unit
scalar((0.0 : Float
Float)))
let Grad[NpArray]
b : struct Grad[T] {
mut value: T
mut grad: T
}
Grad[struct NpArray {
dims: FixedArray[Int]
data: FixedArray[Float]
} derive(@debug.Debug)
NpArray] = (Unit) -> Grad[NpArray]
no_grad(struct NpArray {
dims: FixedArray[Int]
data: FixedArray[Float]
} derive(@debug.Debug)
NpArray::(Float) -> Unit
scalar((0.0 : Float
Float)))
let Linear[Grad[NpArray]]
model : struct Linear[T] {
w: T
b: T
}
Linear[struct Grad[T] {
mut value: T
mut grad: T
}
Grad[struct NpArray {
dims: FixedArray[Int]
data: FixedArray[Float]
} derive(@debug.Debug)
NpArray]] = { T
w, T
b }
let Float
lr : Float
Float = (0.01 : Float
Float)
let Array[Grad[NpArray]]
params : type Array[T]
An Array is a collection of values that supports random access and can
grow in size.
Array[struct Grad[T] {
mut value: T
mut grad: T
}
Grad[struct NpArray {
dims: FixedArray[Int]
data: FixedArray[Float]
} derive(@debug.Debug)
NpArray]] = [Linear[Grad[NpArray]]
model.T
w, Linear[Grad[NpArray]]
model.T
b]
for Int
epoch in Int
0..<=100 {
for Int
idx in Int
0..<Array[Float]
xs.fn[T] Array::length(self : Array[T]) -> Int
Returns the number of elements in the array.
Parameters:
array : The array whose length is to be determined.
Returns the number of elements in the array as an integer.
Example:
test {
let arr : ReadOnlyArray[Int] = [1, 2, 3]
inspect(arr.length(), content="3")
let empty : ReadOnlyArray[Int] = []
inspect(empty.length(), content="0")
}
length() {
let tape : Array[() -> Unit]
tape.fn[T] Array::clear(self : Array[T]) -> Unit
Clears the array, removing all values.
This method has no effect on the allocated capacity of the array, only setting the length to 0.
Example
test {
let v = [3, 4, 5]
v.clear()
@test.assert_eq(v.length(), 0)
}
clear()
for Grad[NpArray]
p in Array[Grad[NpArray]]
params {
Grad[NpArray]
p.T
grad = struct NpArray {
dims: FixedArray[Int]
data: FixedArray[Float]
} derive(@debug.Debug)
NpArray::(Unit) -> NpArray
zeros(Grad[NpArray]
p.T
value.() -> Unit
dims())
}
let Grad[NpArray]
x = (Unit) -> Grad[NpArray]
no_grad(struct NpArray {
dims: FixedArray[Int]
data: FixedArray[Float]
} derive(@debug.Debug)
NpArray::(Float) -> Unit
scalar(Array[Float]
xsfn[T] Array::op_get(self : Array[T], index : Int) -> T
Retrieves an element from the array at the specified index.
Parameters:
array : The array to get the element from.index : The position in the array from which to retrieve the element.
Returns the element at the specified index.
Throws a panic if the index is negative or greater than or equal to the
length of the array.
Example:
test {
let arr : ReadOnlyArray[Int] = [1, 2, 3]
inspect(arr[1], content="2")
}
[idx]))
let Grad[NpArray]
y = (Unit) -> Grad[NpArray]
no_grad(struct NpArray {
dims: FixedArray[Int]
data: FixedArray[Float]
} derive(@debug.Debug)
NpArray::(Float) -> Unit
scalar(Array[Float]
ysfn[T] Array::op_get(self : Array[T], index : Int) -> T
Retrieves an element from the array at the specified index.
Parameters:
array : The array to get the element from.index : The position in the array from which to retrieve the element.
Returns the element at the specified index.
Throws a panic if the index is negative or greater than or equal to the
length of the array.
Example:
test {
let arr : ReadOnlyArray[Int] = [1, 2, 3]
inspect(arr[1], content="2")
}
[idx]))
let Grad[NpArray]
y_hat = Linear[Grad[NpArray]]
model.fn[T : Tensor + Add + Sub + Mul] Linear::forward(self : Linear[T], x : T) -> T
forward(Grad[NpArray]
x)
let Unit
loss = (Grad[NpArray]
y_hat (_ : Grad[NpArray], _ : Grad[NpArray]) -> Grad[NpArray]
- Grad[NpArray]
y).() -> Unit
square()
Unit
loss.() -> Unit
backward()
for Grad[NpArray]
p in Array[Grad[NpArray]]
params {
Grad[NpArray]
p.T
value = Grad[NpArray]
p.T
value (_ : NpArray, _ : NpArray) -> NpArray
- Grad[NpArray]
p.T
grad.(Float) -> NpArray
scale(Float
lr)
}
}
}
}
AI Development
With a complete prototype architecture, letting AI develop became very smooth. Basically, I gave it two or three tasks every night and checked them the next morning. Whether for feature development, performance iteration, comparative validation, or experimental reports, AI programming brought an exponential efficiency improvement compared with old-school programming. Although the overall development took a month, the time actually spent on this project was only my spare time, without affecting work or taking care of children.
Improvements
Grad Optimization
If Tensor is an input, there is no need to record grad, so Option[T], that is, T?, can be used to represent grad:
pub struct Grad[T] {
mut value : T
mut grad : T?
}
For parameters in large models, grad is initialized to 0. When computing gradients backward, there will be many cases of adding 0 and a gradient, wasting time and space. Therefore, add another layer of Option:
pub struct Grad[T] {
mut value : T
mut grad : T??
}
This gives grad three cases:
None=> does not participate in grad computationSome(None)=>gradis 0Some(Some(grad))=>gradis nonzero
Extending Operators
Because Tensor has already been defined, future extensions such as CNN convolution operators must define new traits:
pub(open) trait trait ImageTensor {
fn conv2d(Self, weight : Self, bias : Self, stride : Int, padding : Int) -> Self
fn relu(Self) -> Self
}
ImageTensor {
(Self, Self, Self, Int, Int) -> Self
conv2d(type parameter Self
Self, weight : type parameter Self
Self, bias : type parameter Self
Self, stride : Int
Int, padding : Int
Int) -> type parameter Self
Self
(Self) -> Self
relu(type parameter Self
Self) -> type parameter Self
Self
// ...
}
When defining the forward function for a model, the trait constraints need to be updated:
fn[T : trait Tensor : Add + Sub + Mul {
fn dims(Self) -> FixedArray[Int]
fn zeros(dims : FixedArray[Int]) -> Self
fn scale(Self, Float) -> Self
fn square(Self) -> Self
fn mean(Self) -> Self
fn scalar(Float) -> Self
fn size(Self) -> Int
}
Tensor + trait ImageTensor {
fn conv2d(Self, weight : Self, bias : Self, stride : Int, padding : Int) -> Self
fn relu(Self) -> Self
}
ImageTensor] Renset::(T) -> ?
forward(T
x: type parameter T
T) {
//...
}
GPU Support
struct GPUTensor {
}
impl trait Add {
fn add(Self, Self) -> Self
}
types implementing this trait can use the + operator
Add for struct GPUTensor {
}
GPUTensor with fn Add::add(x : GPUTensor, y : GPUTensor) -> GPUTensor
add(GPUTensor
x : struct GPUTensor {
}
GPUTensor, GPUTensor
y : struct GPUTensor {
}
GPUTensor) -> struct GPUTensor {
}
GPUTensor{
...
}
Using MoonBit's FFI feature, it is convenient to call operator interfaces such as CUDA kernels, cuBLAS, and cuDNN.
Tagless Final
Without realizing it, we had already implemented a Tagless Final architecture, which enables matrix-like flexible extension. The location of concrete function implementations can be very flexible. Other code repositories that depend on moonxi-net can also conveniently extend operators or tensor implementations. For example, this table:
| Trait / backend | NpArray[T] | GpuTensor[T] | Grad[T] |
|---|---|---|---|
Tensor | nparray/impl.mbt | gpu/impl.mbt | grad.mbt |
BlasTensor | nparray/blas_impl.mbt | gpu/impl.mbt | grad.mbt |
ImageTensor | nparray/img_impl.mbt | gpu/impl.mbt | grad.mbt |
Shortcomings
- The global tape needs to be reset manually and does not support second-order gradients.
- The generic
TensortypeTdoes not support compile-time dimension and shape checks. For this,shapeTensorwas defined for runtime checks and shape inference. - During training, GPU memory allocation uses a pool for acceleration. This causes optimizer state and model parameters to have to be updated in place.
Experiments
Experiments were run on MNIST digit recognition and CIFAR-10 image classification, using a 5060 laptop.
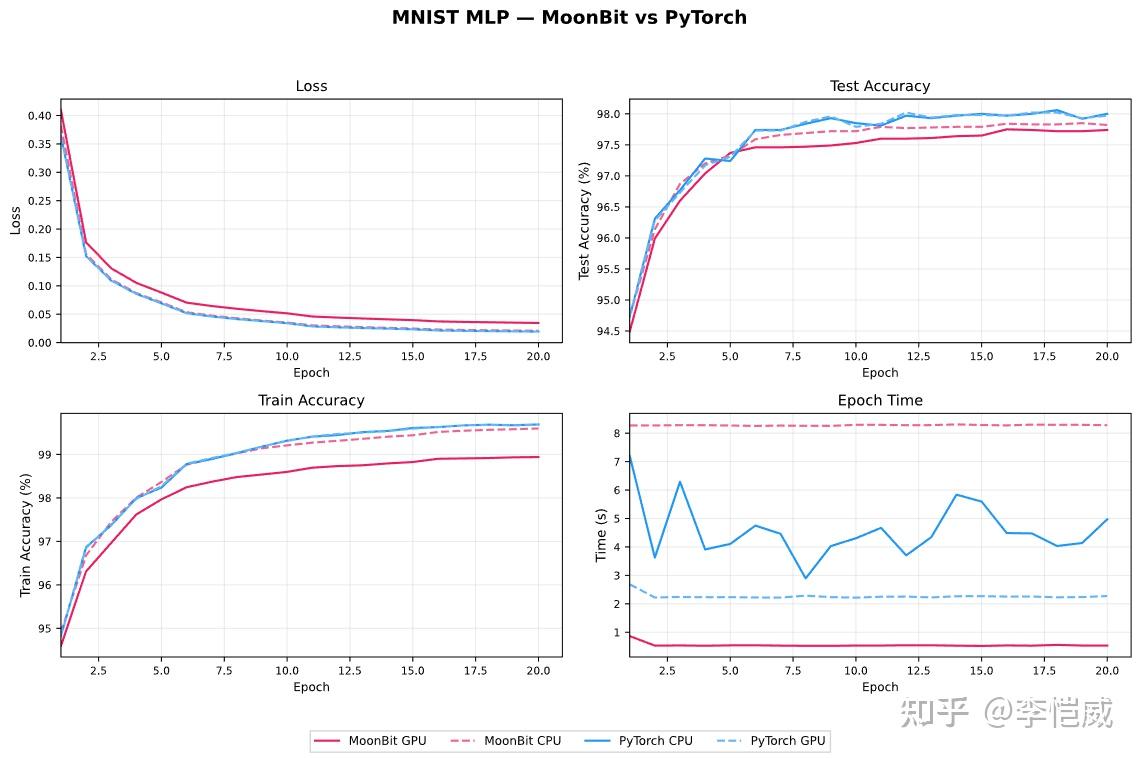
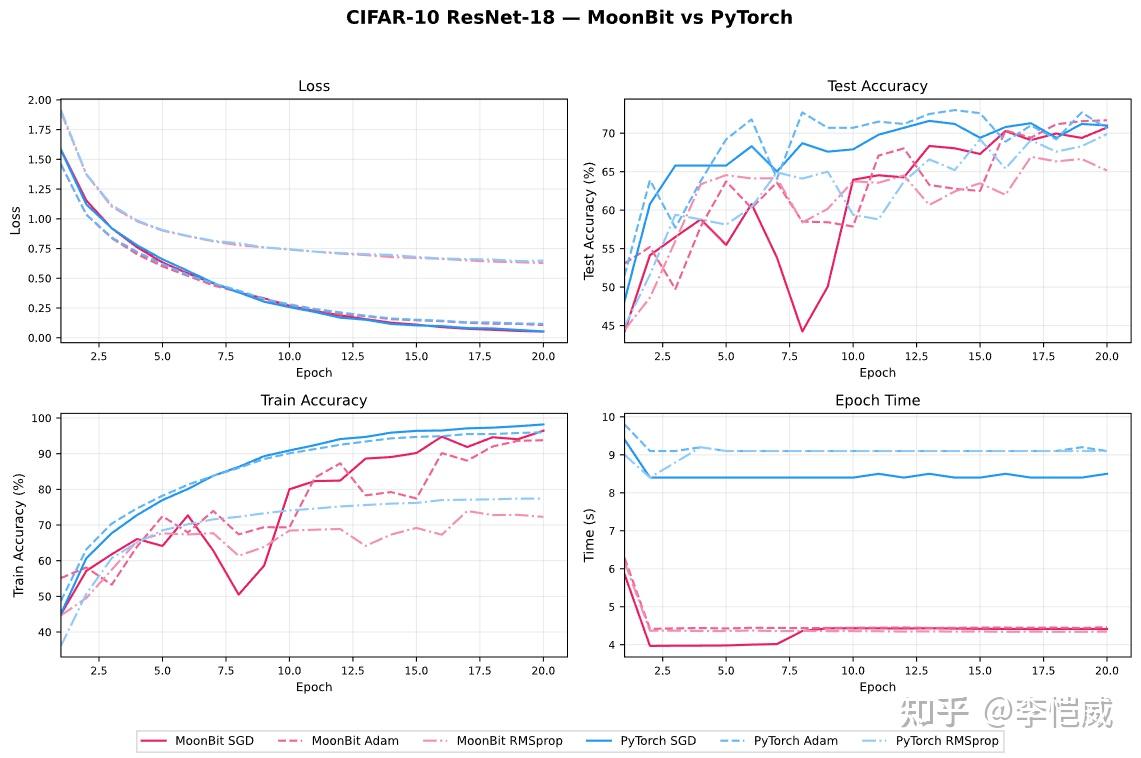
After various optimizations such as operator fusion, moonxi-net's training speed on GPU is about twice as fast as PyTorch. In convergence accuracy, it is slightly lower than the PyTorch version, which may be caused by differences in random seeds, kernel implementations, and so on, and needs further research.
Summary
moonxi-net is a deep learning training framework based on the MoonBit language, using a tagless-final architecture and referencing the PyTorch style. It has both type safety and flexible extensibility, and separates model definitions from multi-backend implementations. After operator fusion optimization, its GPU performance surpasses PyTorch. The first version of moonxi-net was completed in one month, proving the potential of the MoonBit programming language for implementing large system frameworks, while also validating that domestic models plus an open-source harness framework already have sufficient system-code development capability.